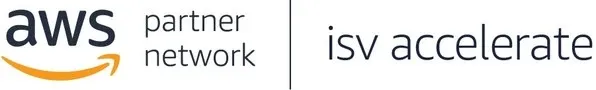Designing Cost Allocation Engines That Finance Trusts: A FinOps Practitioner's Playbook
Only 43% of enterprises track cloud costs at unit level. Here's how to design a cost allocation engine that Finance will trust — across multi-cloud, Kubernetes, AI, and SaaS.
Author
DigiUsher
Read Time
20 min read
Executive Summary
- Only 43% of organisations track cloud costs at the unit level — meaning most enterprises cannot translate what they spend into business language like cost per product, feature, or customer (Gartner, May 2025).
- 84% of organisations say managing cloud spend is their top cloud challenge, with spend expected to grow 28% and budgets exceeded by 17% (Flexera State of the Cloud, 2025).
- 98% of FinOps practitioners now manage AI spend — up from 63% in 2025 — yet most lack attribution models capable of tracing AI costs below model level (FinOps Foundation State of FinOps 2026).
- 58% of teams implemented showback or chargeback models in 2025 — but implementation without accurate underlying allocation produces reports Finance will contest.
- 82% of organisations acknowledge that AI initiatives are making cloud costs harder to manage — a direct consequence of ungoverned AI cost attribution at the allocation layer.
- The Allocation Accuracy Index (AAI) — defined by the FinOps Foundation — is the single KPI that separates Finance-trusted cost data from cost data Finance merely acknowledges.
Why Finance Stops Trusting Cost Data
Finance doesn’t stop trusting cost allocation data because the numbers are wrong. Finance stops trusting it because the numbers are unexplainable.
There is a material difference. A wrong number can be corrected. An unexplainable number creates doubt about every number in the report — including the ones that are correct. When a CFO or VP Finance encounters an allocation line that jumped 34% month-over-month without a corresponding business event, or an “other” bucket that contains $800,000 of unattributed compute, they do not ask for a correction. They ask for a different source of truth.
When tags drift or allocation logic is incomplete, cloud costs stop mapping cleanly to applications, services, and business units. Finance sees unallocated costs, service owners challenge the numbers, and forecasts become harder to defend.
The consequence is structural. Once Finance loses confidence in the allocation model, they route around it. They request raw billing exports from cloud providers and build independent reconciliation workbooks. The FinOps team spends its time defending numbers rather than driving decisions. The chargeback or showback model becomes a reporting artefact rather than a financial governance mechanism.
The design question for a FinOps Operating System is not “how do we give Finance a cost report?” It is “how do we build an allocation engine whose output Finance treats as the single authoritative record?”
The Five Structural Failures That Break Allocation Trust
Every Finance trust breakdown in cost allocation traces to one or more of five structural failures. Diagnosing which failures apply to a given environment determines the rebuild priority.
Failure 1: Multi-Cloud Billing Heterogeneity Without a Normalisation Layer
87% of organisations now pursue multi-cloud strategies. AWS, Azure, and GCP each produce billing exports with different schemas, tag formats, discount representations, and granularity levels. An AWS Reserved Instance is amortised differently from an Azure Reservation. GCP Committed Use Discounts are calculated against a different baseline than AWS Savings Plans. When allocation rules are built on top of provider-native exports without a normalisation layer, two identically-scoped workloads running on different clouds produce different cost representations — and Finance sees inconsistency where there is none.
Failure 2: Shared Cost Distribution Without a Documented Rationale
Shared infrastructure — NAT gateways, Kubernetes control planes, DNS zones, enterprise support tiers, data ingress pipelines — consumes real budget but belongs to no single team. The most common allocation pattern is equal distribution across all cost centres. It is also the pattern that generates the most Finance disputes, because equal distribution bears no relationship to actual consumption. When a product team’s allocated share of shared infrastructure doubles because two new teams onboarded — without any change in that team’s actual usage — Finance will challenge the logic the first time they see it and reject the model the second time.
Failure 3: Kubernetes Costs Rolled to Cluster Level
As Kubernetes has become the default deployment platform for cloud-native applications, the ability to understand per-pod and per-namespace costs has become essential for accurate cost allocation. Kubernetes clusters run multi-tenant workloads on shared nodes. The cloud provider charges at node level. Without a layer that reconstructs workload-level cost from pod scheduling data and resource request ratios, Kubernetes spend appears in allocation reports as a single line attributed to “platform” or “infrastructure” — which is accurate at the infrastructure layer and useless at the business accountability layer.
Failure 4: AI Workloads Aggregated by Model Rather Than Attributed by Team
Only 63% of organisations could track AI spend in 2025 despite rapid adoption. The 37% who could not were not failing to collect billing data — they were failing to attribute it. Azure OpenAI, AWS Bedrock, and Google Vertex AI bill by token consumption at model level. Without API-layer instrumentation that tags each call with a cost centre identifier before it reaches the model endpoint, AI costs appear in the allocation model as a total by model — with no mechanism to distribute them to the teams, applications, or products that drove the consumption.
Failure 5: Allocation Logic That Changes Silently
Allocation rules change for legitimate reasons: organisational restructures, new product launches, changes to shared infrastructure scope, FOCUS schema updates. When those changes are applied silently — without versioning, without Finance notification, without a documented audit trail — the month-over-month variance they produce is indistinguishable from an error. Finance treats unexplained variance and actual errors identically: they stop trusting the data.
The Allocation Architecture Finance Trusts
A Finance-trusted allocation engine has six layers. Each layer addresses one class of structural failure. All six must be present for the output to be Finance-grade.
Cost Allocation Engine — Architecture Layers
──────────────────────────────────────────────────────────────────
Layer 1 FOCUS 1.x Normalisation
─ Ingest from AWS, Azure, GCP, OCI, Kubernetes, SaaS
─ Normalise to FOCUS schema: ChargePeriodStart,
EffectiveCost, ChargeCategory, ResourceId, Tags
─ Amortise commitments consistently across providers
──────────────────────────────────────────────────────────────────
Layer 2 Tagging Governance and Enforcement
─ Mandatory tags defined per resource type
─ Automated tagging at provisioning via IaC/admission control
─ Rule-based attribution for untagged resources (CMDB, account hierarchy)
─ Real-time tag compliance score published to engineering
──────────────────────────────────────────────────────────────────
Layer 3 Cost Domain Mapping
─ Allocation hierarchy mirrors Finance's budget structure
─ Domains: Business Unit > Cost Centre > Product > Environment
─ Engineering view and Finance view generated from same model
──────────────────────────────────────────────────────────────────
Layer 4 Shared Cost Distribution Engine
─ Each shared cost pool assigned a distribution method
─ Methods: proportional, fixed-percentage, equal-share, direct
─ Logic versioned and published to cost centre owners in advance
─ Automated recalculation on consumption driver changes
──────────────────────────────────────────────────────────────────
Layer 5 Kubernetes + AI Attribution Layer
─ K8s: namespace, workload, label — from pod scheduling + requests
─ Control plane: proportional; PV: last owner; Egress: data
─ AI: per-model, per-team token attribution via gateway proxy
─ Token budgets with automated cap enforcement
──────────────────────────────────────────────────────────────────
Layer 6 Finance Publishing and Audit Trail
─ Chargeback/showback aligned to Finance billing cycle
─ Allocation Accuracy Index published as live KPI
─ Rule change log with Finance notification before each cycle
─ Reconciliation view: allocation total ties to provider invoice
──────────────────────────────────────────────────────────────────
Output Finance-Grade Allocation Report
─ 95%+ AAI coverage target
─ Zero unattributed residuals above agreed threshold
─ Auditable methodology document per cost pool
──────────────────────────────────────────────────────────────────
Layer 1: FOCUS 1.x Normalisation
The FinOps Foundation’s FOCUS specification is not a reporting format. It is the data contract that makes a single allocation rule engine operate across heterogeneous cloud billing sources without provider-specific logic branches.
FOCUS defines a standardised set of fields — including ChargeCategory, EffectiveCost, ResourceId, and Tags — that apply uniformly across AWS, Azure, GCP, and OCI. Critically, FOCUS standardises commitment amortisation: Reserved Instance, Savings Plan, Committed Use Discount, and Azure Reservation costs are represented consistently, so Finance sees comparable effective costs across providers rather than rate-card distortions.
The allocation engine built on FOCUS 1.x does not need to know that AWS represents spot instance interruptions differently from GCP preemptible VM terminations. That normalisation happens at Layer 1. Every subsequent allocation rule operates on clean, provider-agnostic data.
Layer 2: Tagging Governance as Allocation Infrastructure
Tagging is not a data hygiene practice. It is the foundational allocation infrastructure. Every resource that lacks a valid cost centre tag is a resource the allocation engine cannot directly attribute — and will either land in the unallocated pool or receive a rule-based attribution that Finance will challenge.
The distinction between enforcement and aspiration is critical here. A tagging policy describes what tags resources should have. Tagging governance enforces it at provisioning — through IaC templates, admission controllers in Kubernetes, or marketplace guardrails — so that untagged resources never reach production. The allocation coverage improvement from moving from policy to enforcement is typically 20–35 percentage points of AAI, achieved in the first 90 days.
For legacy resources that pre-date tagging governance, rule-based attribution from account hierarchy, CMDB relationships, and naming conventions closes the gap without manual tagging remediation at scale.
Layer 3: Cost Domain Mapping — Finance’s Language, Not Engineering’s
The most persistent source of Finance frustration with cost allocation reports is that the allocation structure mirrors how engineering provisions resources, not how Finance manages budgets. Engineering organises by account, subscription, project, cluster, and namespace. Finance organises by business unit, cost centre, product line, and geography.
A Finance-trusted allocation engine maps the engineering hierarchy to the Finance hierarchy through a cost domain model — a structured translation layer that presents the same underlying cost data in the dimensional view each audience needs. Finance sees their cost centre report. Engineering sees their namespace report. Both derive from the same allocation model, with no reconciliation gap between them.
Shared Cost Distribution: The Highest-Stakes Allocation Decision
Shared cost distribution is where most allocation models break down — and where Finance scrutiny is most intense. The reason is straightforward: shared cost distribution involves judgement. Any judgemental allocation creates the possibility that a cost centre owner will challenge their share. If the challenge cannot be answered with evidence, the model loses credibility.
The four distribution methods each carry a different evidentiary burden:
| Method | Basis | Finance Defensibility | Best For |
|---|---|---|---|
| Proportional | Actual consumption driver (CPU-hrs, GB, requests) | High — traces to usage data | Most shared infrastructure |
| Fixed-percentage | Pre-agreed contractual share | Medium — requires periodic review | Contractually scoped services |
| Equal-share | Flat division across consumers | Low — no consumption relationship | Last resort only |
| Direct attribution | Ring-fenced by account or namespace | Highest — no distribution required | Where isolation is feasible |
The FinOps Foundation’s Allocation capability framework is explicit: the allocation strategy must define how costs are mapped to the organisation, and there can be multiple layers of cost allocation and multiple ways to slice cost and usage data — finance may need to see costs divided by cost centre, while engineering teams may need more granular breakdown by application.
The practical implication is that Finance-trusted allocation is not a single model. It is a set of layered, documented distribution decisions — one per shared cost pool — each with a named rationale, a usage driver, and a published review cadence. When Finance challenges a shared cost allocation, the response is a document, not an explanation.
Kubernetes and AI: The Two Allocation Layers That Break Every Legacy Model
Kubernetes Cost Allocation at Namespace Resolution
Kubernetes cost allocation at cluster or node level is not cost allocation. It is cost aggregation under an engineering label. Finance cannot act on “Kubernetes: £2.3M” any more than they can act on “Cloud: £28M.” The business question is which products, teams, and environments drove that £2.3M — and whether the investment produced commensurate business value.
Namespace-level allocation requires three inputs reconstructed from scheduling data: node cost from cloud billing, pod scheduling records from the cluster control plane, and resource request ratios that determine each pod’s proportional claim on node capacity. From these three inputs, the allocation engine produces cost per namespace, per workload, and per label — the granularity at which product and platform teams can own and act on their allocated costs.
Three shared cost layers in Kubernetes require explicit distribution logic:
- Control plane costs — charged at cluster level in managed Kubernetes services; distribute proportionally to compute consumption by namespace
- Persistent volume costs — may outlive the pods that provisioned them; attribute to the last owning namespace with a documented decommission policy
- Egress costs — generated by pods, billed at VPC level; distribute proportionally to data transfer volume by namespace
AI Cost Attribution: From Model Aggregation to Team-Level Governance
For AI, the most important activities fall under understanding cloud usage and cost and quantifying business value — capabilities like allocation, data ingestion, and reporting indicate a strong need to simply understand AI spending.
That understanding requires instrumentation at the API layer, not the billing layer. Azure OpenAI, AWS Bedrock, and Google Vertex AI all bill by token consumption at model level. The billing export shows total token cost per model per month. It contains no information about which team, application, or product call made each API request.
The attribution model requires a gateway proxy — whether a purpose-built AI API gateway or an SDK-level instrumentation layer — that injects a cost centre tag into every API call before it reaches the model endpoint. With that tag in place, the billing-layer token cost is attributable to a named team or product. Without it, AI costs are permanently unallocatable.
Token budget governance is the operational complement to attribution. Each team or application receives a monthly token budget. Consumption is tracked in real time. Automated alerts fire at 70%, 85%, and 100% of budget. Agentic processes that exceed their token budget trigger a kill-switch before overage is incurred. This converts AI cost from a reactive line item — discovered at month-end billing — to a proactively governed allocation that Finance can forecast and budget against.
The Allocation Accuracy Index: The Only Metric Finance Cares About
The Allocation Accuracy Index is the single operational metric that translates allocation engine performance into Finance language.
AAI = (Directly Attributed Costs / Total Infrastructure Costs) × 100
The FinOps Foundation’s definition from its Allocation capability framework is the governance anchor: a higher AAI indicates better financial transparency, more reliable chargeback or showback, and stronger alignment between costs and consumption — supporting accurate budgeting, forecasting, and FinOps decision-making.
The practical threshold levels:
AAI Threshold Scale — Finance Applicability
──────────────────────────────────────────────────────────────────
≥ 95% Finance-Grade
Suitable for formal chargeback, P&L reporting,
board-level cost attribution, and budget variance analysis
──────────────────────────────────────────────────────────────────
80–94% Showback-Grade
Useful for directional cost conversations and team
accountability; residuals create reconciliation friction
──────────────────────────────────────────────────────────────────
60–79% Informational
Directional trend analysis only; too much unallocated
spend for Finance to use in governance decisions
──────────────────────────────────────────────────────────────────
< 60% Unreliable for Governance
Finance will require independent verification before
acting on any allocation derived from this model
──────────────────────────────────────────────────────────────────
The AAI must be published as a live operational metric — visible to Finance, engineering leadership, and the FinOps team simultaneously. An AAI that is only reviewed internally is an allocation coverage target that will never be treated as a financial governance commitment.
The improvement roadmap from a typical entry-state AAI of 55–65% to the 95%+ Finance-grade threshold follows a documented sequence: tagging enforcement at provisioning (adds 20–35 percentage points), rule-based attribution for legacy resources (adds 8–15 points), shared cost distribution modelling (adds 5–10 points), Kubernetes namespace-level attribution (adds 3–8 points), AI workload gateway instrumentation (adds 2–5 points). The sequence is not prescriptive — the largest allocation gap in each environment determines the intervention priority.
How DigiUsher Builds the Allocation Engine Finance Trusts
DigiUsher’s architecture addresses every layer of the Finance trust problem through a FOCUS 1.x native data model that operates from ingestion — not as a post-processing transformation applied to provider-specific exports after the fact.
FOCUS-native normalisation means the allocation rule engine runs on a standardised cost schema across AWS, Azure, GCP, OCI, Kubernetes, SaaS, and marketplace — with commitment amortisation, discount representation, and tag formats handled consistently before any allocation logic is applied. The class of allocation accuracy failures that arise from billing heterogeneity does not exist in the DigiUsher model.
Multi-dimensional allocation supports simultaneous cost attribution across business units, cost centres, product lines, environments, geographies, and projects — with the Finance view and the engineering view generated from the same underlying allocation model. When Finance asks “what did Business Unit A spend on Production workloads in Azure West Europe last month?” and engineering asks “what did the payments namespace spend on GPU compute in that cluster?” — both questions resolve from the same data, with no reconciliation gap.
Kubernetes attribution at namespace, workload, and label level is native — not an add-on. DigiUsher models control plane costs, persistent volume costs, and egress costs with explicit shared distribution logic, configurable by cluster. The result is Finance-grade Kubernetes cost attribution that product teams can own and act on.
AI cost governance operates at the API call layer. DigiUsher instruments per-model, per-team token attribution for Azure OpenAI, AWS Bedrock, Google Vertex AI, and direct API providers — with token budget caps and agentic kill-switches enforced before overage is incurred. AI costs appear in the allocation report attributed to named teams and products, not aggregated at model level.
The Allocation Accuracy Index is a published operational metric within DigiUsher — visible in real time to Finance, engineering leadership, and the FinOps team — with automated escalation when coverage drops below the configured threshold and a rule change log that notifies Finance before each billing cycle.
DigiUsher’s flat enterprise licensing means the allocation engine deploys across the full technology estate — every cloud, every cluster, every SaaS contract, every AI API — without the cost of the governance platform scaling against the cloud spend the platform is governing. The irony of percentage-of-spend FinOps pricing is that it creates a financial incentive to limit the scope of the allocation model. Flat licensing removes that constraint.
For regulated enterprises — banking, insurance, healthcare, government — DigiUsher’s BYOC deployment ensures billing data never leaves the enterprise perimeter. Allocation accuracy requires complete billing data ingestion. BYOC deployment is the architecture that makes complete ingestion compatible with data sovereignty requirements. DigiUsher is deployed in this configuration at institutional scale in regulated financial services environments, delivered globally by SI partners including Infosys and Wipro, and listed on AWS Marketplace (AWS ISV Accelerate Partner) and Azure Marketplace (Azure ISV Co-Sell Ready).
FAQ: Designing Cost Allocation Engines That Finance Trusts
What is a cost allocation engine in FinOps?
A cost allocation engine is the governance infrastructure — data model, attribution rules, shared cost logic, and reporting layer — through which an enterprise maps 100% of its technology spend to accountable owners, cost centres, products, or business outcomes. It is distinct from a cost dashboard or a tagging policy. A dashboard visualises spend that has already been attributed. A tagging policy defines metadata intentions. A cost allocation engine is the operational system that takes heterogeneous billing signals — from AWS, Azure, GCP, Kubernetes, SaaS contracts, and AI inference APIs — normalises them into a common data model, applies deterministic attribution logic, handles shared costs through documented distribution methods, and produces Finance-grade output at the cadence Finance requires.
Organisations with a mature cost allocation engine can answer “what did we spend and who owns it?” within minutes. Organisations without one spend weeks reconciling spreadsheets — and still produce numbers Finance challenges.
Why do FinOps cost allocation models lose Finance’s trust?
Finance stops trusting cost allocation data when four conditions emerge: unexplained month-over-month variance without corresponding business events; unallocated residuals labelled as “other” or “shared” with no documented distribution logic; numbers that cannot be reconciled to the cloud provider invoice; and AI or Kubernetes costs that appear as lump-sum charges with no team-level breakdown.
Each condition is a symptom of a structural failure — not a data problem. The most common root causes are inconsistent tagging across cloud providers; shared infrastructure costs distributed by headcount rather than consumption; Kubernetes costs rolled up to cluster level; and AI token costs aggregated by model. When Finance encounters unexplainable variance, they stop acting on the data — which is the mechanism through which the entire FinOps programme loses its influence over budget decisions.
What is the Allocation Accuracy Index (AAI) and what score should enterprises target?
The Allocation Accuracy Index (AAI) is a FinOps Foundation KPI that measures the percentage of total infrastructure costs directly and accurately attributed to responsible teams, products, or business units: AAI = (Directly Attributed Costs / Total Infrastructure Costs) × 100. An AAI above 95% is the threshold at which Finance can confidently use allocation data for chargeback, formal P&L reporting, and budget variance analysis. Between 80% and 95%, data is useful for showback but carries enough unallocated residual to create reconciliation disputes. Below 80%, allocation data is unreliable for financial governance. The AAI must be published as a live operational metric — not reviewed internally — with a documented improvement roadmap and an explicit 95%+ target.
How should enterprises handle shared cloud costs in their allocation model?
There are four documented distribution methods: proportional (based on actual consumption drivers — most defensible), fixed-percentage (pre-agreed shares — requires periodic review), equal-share (flat division — generates the most Finance disputes), and direct attribution (ring-fenced by account or namespace — most accurate where feasible). The FinOps Foundation is explicit: shared cost distribution logic must be documented, consistently applied, and communicated to cost centre owners before chargeback is published. Finance disputes arise not from the allocation amount itself, but from the absence of a documented, auditable rationale.
How does FOCUS improve cost allocation accuracy across multi-cloud environments?
FOCUS (FinOps Open Cost and Usage Specification) normalises cloud billing data into a provider-agnostic schema — enabling a single allocation rule engine to operate across AWS, Azure, and GCP without provider-specific logic branches. For allocation accuracy, FOCUS delivers three concrete benefits: consistent commitment amortisation across providers; a single tagging governance layer that enforces attribution metadata at ingestion; and explicit fields for AI workload cost attribution within the same allocation model as infrastructure spend. Organisations running FOCUS-native allocation engines consistently achieve higher AAI scores than those applying provider-specific logic, because the normalisation layer eliminates attribution errors that arise from billing format inconsistency.
How should Kubernetes costs be allocated to achieve Finance-grade accuracy?
Kubernetes cost allocation requires reconstructing workload-level costs from three inputs: node cost from cloud billing, pod scheduling data, and resource request/limit ratios. This produces cost per namespace, per pod, and per label — the attribution granularity Finance needs to assign costs to product teams and applications. Three additional shared cost layers require explicit allocation decisions: control plane costs (distribute proportionally to compute consumption), persistent volume costs (attribute to last owning namespace), and egress costs (distribute proportionally to data transfer volume). Finance-grade Kubernetes allocation instruments all three layers with documented distribution logic and publishes namespace-level cost reports on the same cadence as cloud provider billing.
What does a Finance-trusted cost allocation engine look like for AI workloads in 2026?
A Finance-trusted AI cost allocation model requires four capabilities: per-model attribution (costs tracked separately for each foundation model); per-team attribution (each API call tagged with a cost centre identifier through SDK instrumentation or a gateway proxy); token budget governance (monthly budgets per team with automated cap enforcement before overage); and unit economics bridging (AI costs expressed as cost per AI-assisted transaction, cost per Copilot seat-hour, or cost per model inference). 98% of FinOps practitioners now manage AI spend — but most aggregate costs at model level rather than attributing them to the teams and products that drove the consumption. That attribution gap is the primary barrier to Finance-grade AI cost governance in 2026.
How does DigiUsher build a cost allocation engine that Finance trusts?
DigiUsher’s FOCUS 1.x native architecture means the allocation engine operates on a normalised cost data model from ingestion — eliminating allocation accuracy failures from billing format inconsistency. Multi-dimensional allocation supports simultaneous attribution across business units, cost centres, environments, and geographies. Kubernetes allocation operates at namespace, workload, and label level with explicit shared cost modelling. AI workloads are attributed per-model and per-team through gateway instrumentation, with token budget caps enforced by agentic kill-switches. The Allocation Accuracy Index is published as a live operational metric. Flat enterprise licensing means the allocation engine covers the full technology estate without percentage-of-spend cost scaling. BYOC deployment satisfies data sovereignty requirements for regulated enterprises. DigiUsher is delivered globally by Infosys and Wipro, listed on AWS Marketplace as an ISV Accelerate Partner, and Azure Marketplace as ISV Co-Sell Ready.
References
- FinOps Foundation — State of FinOps 2026 (data.finops.org)
- FinOps Foundation — State of FinOps 2025 (data.finops.org/2025-report)
- FinOps Foundation — Allocation Capability Framework (finops.org)
- Gartner — Cloud Financial Management, May 2025 (via TechRadar / ramp.com)
- Flexera — State of the Cloud 2025
- Deloitte — FinOps tooling cost benchmark, 2025 (via nops.io)
- Amnic — Cloud Cost Trends 2025 and 2026 (amnic.com)
- Cloudaware — Expert Guide to Cloud Cost Allocation Strategies 2026 (cloudaware.com)
- Cloudaware — Cloud Cost Analysis 2026 (cloudaware.com)
- Tech Insider — FinOps in 2026: How CFOs Are Finally Taming Runaway Cloud Costs (tech-insider.org)
- Webvillee — FinOps Operating Model 2026: Roles, KPIs and Accountability (webvillee.com)
- NStarX — Cloud Cost Optimisation with AI (nstarxinc.com)
The cost allocation engine is not a reporting tool. It is the infrastructure through which Finance decides whether to trust the numbers that govern $100M+ technology investment decisions. Build it with the same rigour you apply to the infrastructure it governs.
Ready to Build the Allocation Engine Finance Will Actually Use?
DigiUsher’s FOCUS-native FinOps Operating System builds Finance-trusted cost allocation across your full technology estate — multi-cloud, Kubernetes, AI workloads, and SaaS — in a single, auditable model. Our enterprise clients achieve 95%+ Allocation Accuracy Index scores and eliminate the quarterly Finance reconciliation cycle that consumes FinOps team capacity.
Request a Demo
See how these ideas translate into measurable cloud and AI savings.
Book a tailored DigiUsher walkthrough to connect the strategy in this article to your team's cost visibility, governance, and optimization priorities.
Continue Reading
More from the DigiUsher editorial team.
Board-Level AI ROI: Why $600B in Investment Is Delivering Single-Digit Returns — and What Fixes It
Only 7% of CFOs see high ROI from AI despite $270B in enterprise spend forecast for 2026. Here's the governance framework boards are demanding — and why cost attribution is the missing layer.
Explore article
Board-Level Cloud and Data Centre ROI: Governing the Full Technology Estate in 2026
Cloud waste runs at 29-35% of spend. GPU idle time hits 30-60%. Data centre costs surpass $650B in 2026. Here is the board-level governance framework that connects every infrastructure dollar to measurable business value.
Explore article
The Broken Cost Schema Problem: Why Every FinOps Team Is Solving the Same Problem from Scratch (Blog 1/5 Series)
80% of enterprises can't track cloud spend accurately across providers. The reason isn't discipline — it's three incompatible billing schemas. FOCUS changes the equation.
Explore article