The Broken Cost Schema Problem: Why Every FinOps Team Is Solving the Same Problem from Scratch (Blog 1/5 Series)
80% of enterprises can't track cloud spend accurately across providers. The reason isn't discipline — it's three incompatible billing schemas. FOCUS changes the equation.
Global public cloud spending reached $723 billion in 2025 and is projected to cross $1 trillion in 2026. Of that, 29% is wasted — $182 billion in compute, storage, and services that delivered no business value. The waste figure has stubbornly refused to decline for five consecutive years, even as organisations invested heavily in FinOps teams, tooling, and optimisation programmes.
The reason the number does not move is not a discipline problem. It is a data problem.
Only 39% of enterprises can accurately track unified cloud spend across all the providers they use. That statistic — from CloudZero’s 2024 State of Cloud Cost Intelligence — means 61% of organisations are making financial decisions about their largest controllable operating expense using partial, non-normalised data. They cannot see what they cannot govern. They cannot govern what they cannot measure. And they cannot measure accurately because every provider in their estate produces billing data in a completely different format, using completely different terminology, with completely different definitions of what the word “cost” even means.
This is the cloud billing schema problem. It is the industry’s most expensive hidden tax. And until the FinOps Open Cost and Usage Specification, there was no architectural answer to it.
The Three-Schema Problem: Why Multi-Cloud Reporting Starts Broken
When a FinOps practitioner sits down to build a unified multi-cloud cost report, the first question they face is not “where is the waste?” The first question is “what do they each call compute?”
AWS exports its Cost and Usage Report with hundreds of columns carrying names like lineItem/UsageType, lineItem/Operation, product/instanceType, and product/servicecode. The service category for compute is inferred from a combination of columns, not a dedicated field. The cost of a resource on a particular day depends on which of the several cost columns you choose: lineItem/BlendedCost, lineItem/UnblendedCost, lineItem/NetUnblendedCost, or reservation/EffectiveCost — each of which produces a different number and is correct for a different analytical purpose.
Azure exports entirely different CSV files using MeterCategory, MeterSubCategory, ConsumedService, and ResourceType as its primary dimensions. Azure’s equivalent of AWS’s unblended cost is CostInBillingCurrency. Its equivalent of AWS’s amortised cost is CostInBillingCurrencyAmortised. These fields are not in the same positions, do not use the same naming conventions, and do not carry the same values for the same underlying resources.
Google Cloud pipes billing data into BigQuery using service.description and sku.description as the primary service identifiers. GCP’s cost model differs further: credits, discounts, and adjustments appear as separate rows rather than adjustments to existing cost rows, requiring union queries across multiple row types to arrive at an effective cost figure comparable to what AWS or Azure would show in a single row.
Three clouds. Three schemas. Three definitions of cost. Before a FinOps team can ask “what did we spend on compute last month across AWS and Azure?” they must first write ETL pipelines that ingest each provider’s format, map each provider’s service taxonomy to a common internal category, resolve incompatible cost column definitions across providers, and validate that the resulting unified number is actually comparable. The query that should take 30 seconds takes three months of engineering effort and produces a report that needs to be re-validated every time any provider updates their billing format — which happens multiple times per year.
80% of organisations now run workloads across multiple public cloud providers (Virtana 2025). Every one of them lives with this problem every day.
The Three-Schema Problem: What "Compute Spend Last Month" Requires
──────────────────────────────────────────────────────────────────────────────
Step AWS Azure GCP
──────────────────────────────────────────────────────────────────────────────
Identify compute rows Filter UsageType Filter MeterCat Filter service
for "BoxUsage" for "Virtual description for
Machines" "Compute Engine"
Select effective cost col reservation/ CostInBillingCurr Sum cost where
EffectiveCost AmortisedActual adjustment_type
OR OR Cost != DISCOUNT
lineItem/
NetUnblendedCost
Handle commitment spend Amortise RI/SP Amortise Committed Use
line items Reservation Discounts appear
separately usage as negative rows
Normalise to common Custom mapping: Custom mapping: Custom mapping:
service category EC2 → Compute VMs → Compute GCE → Compute
Validate cross-provider Manual QA against Manual QA against Manual QA against
consistency each provider's each provider's each provider's
console cost reports billing export
──────────────────────────────────────────────────────────────────────────────
Total: 3 ETL pipelines, 3 mapping tables, ongoing maintenance per provider change
──────────────────────────────────────────────────────────────────────────────The Hidden ETL Tax: What Billing Data Fragmentation Actually Costs
The cost of this problem does not appear on any cloud invoice. It is absorbed inside FinOps engineering capacity — buried in sprint velocity, personnel costs, and the opportunity cost of analytical work that never happened because the data was not ready.
82% of cloud decision-makers name managing cloud spend as their primary challenge (Flexera 2025). Not security. Not compliance. Not developer skills. The biggest problem with the largest technology cost on most enterprise balance sheets is that organisations cannot see it accurately enough to manage it. The primary structural reason for that failure is incompatible billing schemas.
The engineering dimension of this problem is concrete. Every enterprise running three clouds maintains at minimum three separate billing data pipelines — more if they also ingest Kubernetes cluster-level cost data, SaaS billing exports, or AI provider invoices. Each pipeline must be designed, built, tested, deployed, monitored, and maintained by engineers whose time has measurable value. Each pipeline must be updated when a provider changes their billing format — and AWS alone issues multiple format changes per year. The CUR column additions, reservation pricing model changes, and Savings Plan amortisation updates that land silently in AWS billing exports routinely break downstream analytics until pipelines are patched.
The financial dimension compounds further when tooling cost is factored in. FinOps tools priced at a percentage of cloud spend — industry data from Deloitte suggests 3–5% of the cloud bill at the high end — create a structural misalignment: the cost of the tool scales with the very problem it is supposed to solve. An organisation spending $10 million per month on cloud infrastructure pays $300,000–$500,000 per year in tool cost on top of the engineering overhead of maintaining the normalisation pipelines the tool is supposed to replace. The billing schema problem is not just invisible — it is self-reinforcing.
The scope expansion happening in FinOps makes this worse. In 2026, 90% of FinOps teams now govern SaaS spend alongside cloud infrastructure — up from 65% the prior year (FinOps Foundation State of FinOps 2026). Each SaaS provider adds a new billing format to the normalisation backlog. 98% of FinOps teams now govern AI workload costs, up from 63% in 2025 — and AI providers introduce an entirely new class of pricing complexity: tokens, inference units, GPU-hours, context windows, and model versions, none of which map cleanly onto existing cloud billing schemas.
The practitioner quoted in the FinOps Foundation’s 2026 report captures the progression precisely: “First they asked us to fix cloud. Then fix the software mess. Now it’s fix the contract and license mess, now fix the data centre.” Every new domain added to a FinOps team’s scope without a common data model is another schema to ingest, another mapping to build, and another pipeline to maintain. The ETL tax compounds with every expansion.
Why Every Previous Standardisation Attempt Failed
The cloud billing schema problem is not new. FinOps teams and platform vendors recognised it as soon as multi-cloud became standard enterprise practice. The solutions that emerged before FOCUS shared a common structural flaw: they were built inside the problem rather than above it.
Every FinOps platform that attempted billing data normalisation before FOCUS did so by creating a proprietary internal schema. The platform ingested AWS CUR data, Azure billing exports, and GCP BigQuery exports, and translated each into the vendor’s own internal data model using custom mapping logic the vendor owned and maintained. This approach solves the normalisation problem for the platform’s customers — as long as they remain customers.
The problem it creates is a second-order version of the same dependency. Organisations move from depending on AWS’s schema, Azure’s schema, and GCP’s schema to depending on their FinOps vendor’s proprietary schema. Switching FinOps platforms requires migrating an entire data model, rebuilding cost allocation hierarchies from scratch, re-mapping service taxonomies, and retraining finance and engineering teams on new terminology. The lock-in created by a proprietary normalisation layer is, in practice, more durable than the cloud provider lock-in it was supposed to address — because at least cloud providers produce public documentation for their billing formats.
The FinOps Foundation’s FOCUS specification is structurally different because it sits above any single vendor’s interest. FOCUS was initiated in 2023 with contributions from the cloud providers themselves — AWS, Azure, Google Cloud, and Oracle all participated in the working group that produced the specification. When the organisations that generate the billing data are also the organisations defining the standard for that data’s format, the normalisation problem dissolves at the source. Providers do not need to be translated because they have agreed to speak the same language natively.
This is the inflection point that previous standardisation attempts could never reach: hyperscaler buy-in. No FinOps platform vendor, however large, could compel AWS to change the structure of the CUR or Azure to restructure their billing export. The FinOps Foundation, as a neutral Linux Foundation project, achieved what no vendor could.
FOCUS Changes the Architectural Equation
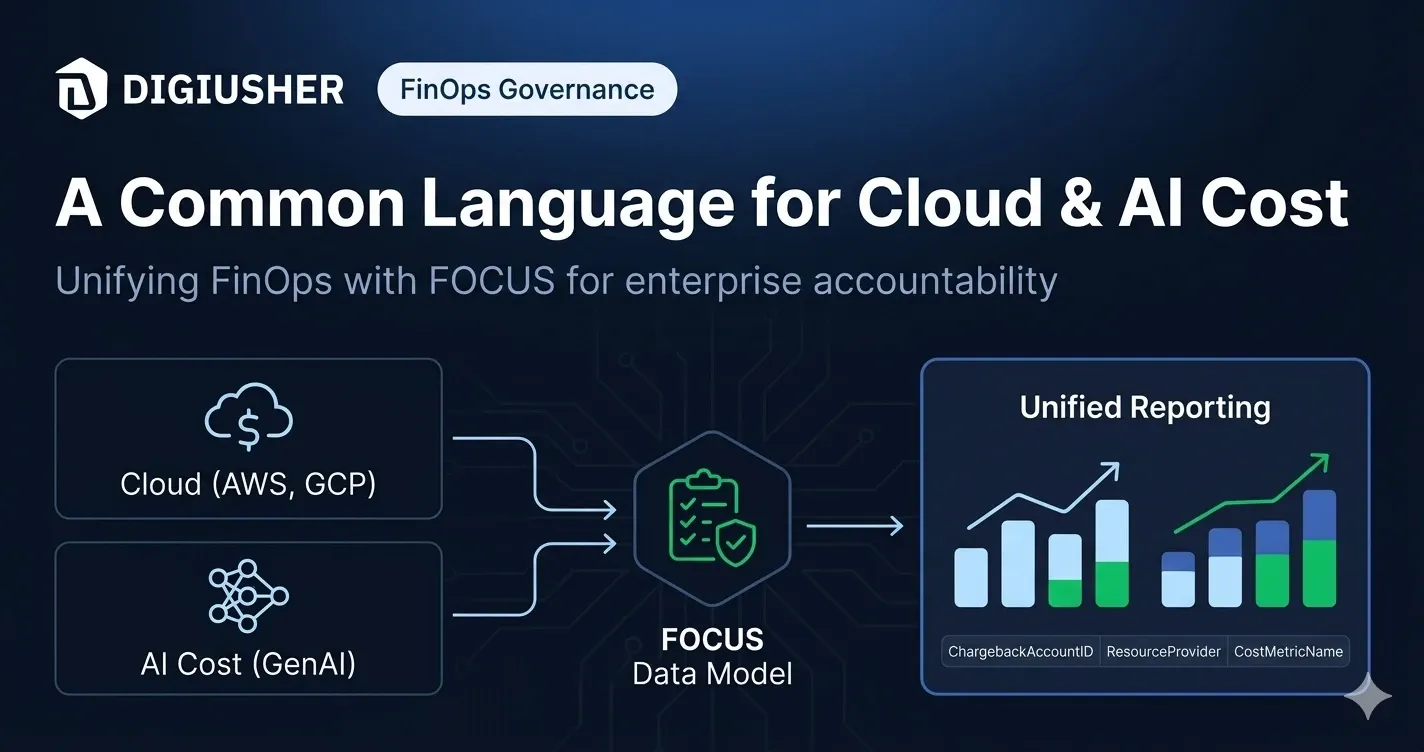
The FinOps Open Cost and Usage Specification defines a vendor-neutral schema for technology billing data. Rather than each provider inventing a billing format, FOCUS specifies a set of columns, cost metrics, charge type definitions, and service taxonomies that any provider can implement as a native data export. When AWS exports FOCUS-format billing data and Azure exports FOCUS-format billing data, a single SQL query against a FOCUS-aware analytics system can compare compute spend across both providers without any intermediate transformation.
FOCUS 1.1 (ratified November 2024) deepened support for cloud provider billing data and improved the ETL metadata that powers multi-cloud analysis pipelines. FOCUS 1.2 (ratified May 2025) was the specification’s most consequential release: it expanded coverage beyond cloud infrastructure to include SaaS and PaaS billing data in the same schema, meaning a single dashboard can now cover an organisation’s full Cloud+ technology estate — cloud, SaaS, and AI provider costs — in one query. FOCUS 1.2 also introduced AI token lifecycle tracking (credit purchase patterns, burn-down analysis, and surprise overage prevention), invoice-level reconciliation, and multi-currency normalisation. FOCUS 1.3 (ratified December 2025) added three capabilities enterprise FinOps teams have been waiting for: a structured methodology for shared cost allocation across Kubernetes workloads and multi-tenant infrastructure, a dedicated Contract Commitments dataset that isolates reserved capacity terms from cost and usage rows, and data freshness indicators that tell practitioners whether billing data is current or stale.
The practical impact of FOCUS at the schema level is significant. Microsoft’s own FOCUS documentation reports that FOCUS-format billing exports produce 49% fewer rows than the combined actual-plus-amortised native datasets, and a data file approximately 30% smaller in size. Fewer rows and smaller files mean lower data processing costs, faster query execution, and less storage overhead — directly reducing the computational cost of running FinOps analytics at scale.
As of FOCUS 1.3, more than 11 technology providers export native FOCUS billing data: AWS, Microsoft Azure, Google Cloud Platform, Oracle Cloud Infrastructure, Alibaba Cloud, Databricks, Grafana, OVH Cloud, Huawei, and Tencent, with more providers announcing conformance through the FinOps Foundation’s Conformance Programme. 96 of the Fortune 100 participate in FinOps Foundation programmes. The specification has moved from a working group project to a production standard in less than 30 months.
57% of FinOps practitioners plan to adopt FOCUS in the next 12 months (FinOps Foundation State of FinOps 2025). Only 18% say they have no plans to adopt it at all — the lowest non-adoption intent the specification has recorded.
FOCUS-Native vs FOCUS-Compatible: The Distinction That Determines Your Platform’s Ceiling
Not every FinOps platform that references FOCUS is a FOCUS-native platform. The distinction matters significantly for enterprise buyers, and it is the distinction most frequently obscured in vendor marketing.
A FOCUS-compatible platform ingests billing data from cloud providers and maps or translates that data into FOCUS format — either as an output format for export or as a query-time transformation layer applied to data stored in the platform’s proprietary schema. The underlying data model remains proprietary. FOCUS is applied after the fact.
A FOCUS-native platform uses FOCUS as the primary data model from the moment of ingestion. Every cost record from every provider is stored using FOCUS columns. Every query runs against FOCUS dimensions. Every allocation, every chargeback, every anomaly detection rule, and every AI token attribution model operates on FOCUS-native data — not on a translation of proprietary data into FOCUS. There is no intermediate schema. There is no mapping table between what a provider calls a service and what the platform calls it.
The practical consequences of this distinction compound across every FinOps capability.
For cost allocation, a FOCUS-native platform applies ServiceCategory consistently across AWS, Azure, GCP, and Databricks — because the data was ingested in FOCUS format, ServiceCategory carries the same semantics across all providers. A compatibility layer applies ServiceCategory as a derived field mapped from each provider’s native service taxonomy, introducing the risk of mapping inconsistencies that only surface at report time.
For AI cost governance, a FOCUS-native platform can ingest Databricks and Azure OpenAI billing data in FOCUS format — both providers now produce native FOCUS exports — and apply token attribution, unit economics, and agentic chain cost analysis against a consistent ChargeType and ServiceCategory schema shared with the rest of the estate. A compatibility layer must map Databricks’ billing model and Azure OpenAI’s token billing model separately into its proprietary schema before any unified AI-and-cloud analysis can take place.
For regulated industries, a FOCUS-native platform can offer self-hosted deployment — BYOC architecture where the organisation’s billing data never leaves their own infrastructure — while maintaining full FOCUS schema integrity. The data model is defined by the open specification, not the vendor’s proprietary format, which means on-premises deployment does not compromise the schema consistency that makes multi-cloud analytics possible.
FOCUS-Native vs FOCUS-Compatible: What Enterprise Buyers Need to Know
──────────────────────────────────────────────────────────────────────────────
Capability FOCUS-Native FOCUS-Compatible
──────────────────────────────────────────────────────────────────────────────
Primary data model FOCUS schema Proprietary schema
from ingestion + FOCUS translation layer
Cross-provider query Single SQL query, Query against
surface FOCUS columns, mapped/translated
no joins proprietary schema
Cost metric consistency EffectiveCost, Derived from
across providers BilledCost identical proprietary cost
per FOCUS spec columns per provider
FOCUS version upgrade Schema update at Translation layer
impact on your data data layer only requires update +
— zero migration dashboard migration
New provider onboarding Provider with FOCUS New mapping table
(when provider adds FOCUS export = zero required per provider
native support) engineering work regardless of FOCUS
Regulated/self-hosted FOCUS schema Proprietary schema
deployment (BYOC) integrity preserved in self-hosted
on-premises environment
──────────────────────────────────────────────────────────────────────────────What FOCUS-Native Architecture Unlocks for the Enterprise
The case for FOCUS-native architecture is ultimately not a case about data engineering. It is a case about time to insight, breadth of governance, and the compound value created when the cost schema is no longer a bottleneck.
When billing data normalisation is handled at the architectural level — when the platform’s data model and the specification’s data model are the same thing — FinOps capacity that was previously consumed by ETL maintenance becomes available for the work the function is actually supposed to do: identifying waste, governing commitments, attributing AI spend to business outcomes, and presenting CFO-level capital allocation intelligence to the board.
The practitioner community’s own language signals where the discipline is heading. The FinOps Foundation updated its mission in 2026 from “advancing the people who manage the value of cloud” to “advancing the people who manage the value of technology.” One sentence change. An enormous scope shift. As FinOps expands to govern AI workloads, Databricks and Snowflake data platform costs, SaaS subscriptions, and on-premises infrastructure alongside multi-cloud, the cost of maintaining separate normalisation pipelines for each new technology category becomes the primary constraint on the practice’s ability to scale.
DigiUsher was built on FOCUS-native architecture from the ground up — not as a retrospective compatibility decision but as an architectural commitment made when the specification was in its earliest stages. Every cost record from every supported provider — AWS, Azure, GCP, OCI, Alibaba Cloud, Kubernetes clusters (EKS, AKS, GKE, OKE), Azure OpenAI, AWS Bedrock, Google Vertex AI, Databricks, Snowflake ML, and SaaS providers — is ingested, stored, and queried using FOCUS columns natively. There is no proprietary intermediate schema. There is no mapping table between DigiUsher’s data model and FOCUS. They are the same.
That architectural choice is what allows DigiUsher to deliver multi-cloud cost allocation, AI token attribution, Kubernetes namespace chargeback, and SaaS unit economics from a single query surface — without custom ETL pipelines, without intermediate translation layers, and without the maintenance overhead that turns FinOps teams into data engineers. For regulated enterprises — including banking and financial services organisations running DigiUsher in self-hosted BYOC deployments where billing data never leaves their own infrastructure — FOCUS-native architecture means schema integrity is maintained whether the platform runs in DigiUsher’s managed cloud or inside the organisation’s own environment. The cost data model is defined by an open specification, not by the vendor.
Global SI partners — including Infosys and Wipro — deliver DigiUsher to enterprise clients across complex multi-cloud, multi-geography environments. FOCUS-native architecture is what makes those enterprise-scale deployments tractable: delivery teams work against a specification-conformant data model, not a proprietary vendor schema that only the vendor fully understands.
DigiUsher is available on AWS Marketplace (AWS ISV Accelerate Partner), Azure Marketplace (Azure ISV Co-Sell Ready, MACC-eligible), and Google Cloud Marketplace — meeting enterprise procurement teams wherever their primary cloud commitment sits.
Frequently Asked Questions
What is the cloud billing schema problem in FinOps?
The cloud billing schema problem is the structural incompatibility between the billing data formats produced by different technology providers. AWS, Azure, and GCP each define service categories, cost columns, and charge type terminology using proprietary schemas that are not interoperable. Before any cross-provider analysis can happen — cost allocation, commitment coverage, anomaly detection, or unit economics — an enterprise FinOps team must build ETL pipelines that ingest, normalise, and map each provider’s schema to a common internal format. Those pipelines require ongoing maintenance every time a provider changes their billing format. The FinOps Open Cost and Usage Specification (FOCUS) was created specifically to eliminate this problem by defining a single, vendor-neutral schema that all providers can implement as a native export format.
What is FOCUS-native architecture and why does it matter?
FOCUS-native architecture is a FinOps platform design in which FOCUS serves as the primary data model — not an export layer or compatibility wrapper applied to a proprietary billing format. In a FOCUS-native platform, every cost record from every provider is ingested, stored, queried, and reported using FOCUS columns, terminology, and cost metrics directly, with no intermediate schema translation. This architectural distinction determines the platform’s ceiling across every FinOps capability: cost allocation consistency, AI token attribution, Kubernetes chargeback, SaaS unit economics, and BYOC deployment for regulated industries. A compatibility layer introduces a lossy translation between the raw billing data and the analytical surface; a FOCUS-native platform eliminates that translation entirely.
How much does cloud billing data normalisation cost enterprises?
The direct cost is embedded inside FinOps engineering capacity — ETL pipeline design, build, testing, and ongoing maintenance across three or more cloud providers, each of which issues multiple billing format changes per year. The indirect cost is visible in the data: only 39% of enterprises can accurately track unified cloud spend across all providers (CloudZero 2024), and 82% name managing cloud spend as their primary challenge (Flexera 2025). FinOps tooling priced at 3–5% of cloud spend (Deloitte 2025) compounds this cost further, scaling against the problem it is supposed to solve rather than eliminating it.
What is FOCUS and who supports it?
FOCUS is the FinOps Open Cost and Usage Specification — an open technical standard maintained by the FinOps Foundation under the Linux Foundation. As of FOCUS 1.3 (ratified December 2025), the specification is supported natively by 11+ providers including AWS, Microsoft Azure, Google Cloud, Oracle Cloud Infrastructure, Alibaba Cloud, and Databricks. FOCUS 1.2 (ratified May 2025) expanded coverage to SaaS, PaaS, and AI token lifecycle tracking. 96 of the Fortune 100 participate in FinOps Foundation programmes. 57% of FinOps practitioners plan FOCUS adoption in the next 12 months.
Why did previous attempts to standardise cloud billing data fail?
Previous normalisation attempts failed because they were built inside the problem rather than above it. Every FinOps platform that attempted normalisation before FOCUS did so by creating a proprietary internal schema — translating AWS, Azure, and GCP data into the vendor’s own data model. This solved the immediate problem while creating a new one: organisations moved from cloud provider lock-in to FinOps vendor lock-in. Switching platforms required migrating an entire data model. FOCUS is structurally different: it is an open, community-governed standard with contributions from the cloud providers themselves. When the data generators implement the same standard, the normalisation problem dissolves at the source.
What does FinOps scope expansion mean for the billing schema problem?
Scope expansion makes the problem significantly worse without a FOCUS-native platform. In 2026, 90% of FinOps teams govern SaaS (up from 65%), and 98% govern AI spend (up from 63%) — each new category adding a new billing format to the normalisation backlog. For organisations using proprietary normalisation layers, every new technology category adds a new ETL pipeline, a new mapping table, and a new maintenance burden. For FOCUS-native platforms, every new provider that implements FOCUS natively adds a new data source to an existing schema with zero additional engineering overhead.
How should enterprises evaluate FinOps platforms for FOCUS architecture?
Enterprises should ask four questions: Is FOCUS your primary data model or an export format? Can you run a single SQL query across all providers using FOCUS columns without intermediate processing? When FOCUS releases a new version, does the update require schema migration on our end? Do you support the full FOCUS cost metric set — BilledCost, EffectiveCost, ListCost, ContractedCost — with consistent definitions across all providers? A platform that cannot answer all four questions cleanly is operating a compatibility layer, not a native architecture.
What is the relationship between FOCUS and the FinOps Foundation?
FOCUS is a project of the FinOps Foundation, a non-profit trade association under the Linux Foundation. The specification was initiated in 2023 and is governed by a FOCUS Steering Committee, maintained by an open working group, and validated through a formal Conformance Programme. The FinOps Foundation releases FOCUS updates approximately twice per year. As of May 2026, the specification has reached version 1.3, with coverage extending from cloud infrastructure to SaaS, PaaS, AI token billing, shared cost allocation, and contract commitment tracking.
References
- FinOps Foundation — State of FinOps Report 2026 — Primary source for scope expansion statistics: 98% AI adoption, 90% SaaS governance, FinOps mission change from “cloud” to “technology” (2026)
- FinOps Foundation — State of FinOps Report 2025 — Primary source for FOCUS adoption intent: 57% plan adoption, 18% not planning adoption, pipeline integration as primary adoption method (2025)
- FinOps Foundation — FOCUS Specification — Primary source for FOCUS version history: 1.1 (November 2024), 1.2 (May 2025), 1.3 (December 2025); provider support and Conformance Programme
- Linux Foundation Press — FinOps Foundation Launches FOCUS 1.3 — Source for FOCUS 1.3 capabilities: shared cost allocation, Contract Commitments dataset, data freshness; 11+ provider support confirmation (December 2025)
- PR Newswire — FOCUS 1.2 General Availability — Source for FOCUS 1.2 Cloud+ unified reporting, SaaS/PaaS inclusion, Alibaba Cloud, Databricks, and Grafana addition (June 2025)
- Microsoft Azure — What is FOCUS? — Source for FOCUS dataset efficiency: 49% fewer rows, ~30% smaller data size vs native actual-plus-amortised datasets (2025)
- Flexera — State of the Cloud Report 2026 — Source for 29% wasted IaaS/PaaS spend (increased from prior years), hybrid cloud adoption at 73%, all respondents using GenAI (2026)
- Flexera — State of the Cloud Report 2025 — Source for 82% citing cloud spend management as primary challenge; 59% expanding FinOps teams; 27% waste rate (2025)
- Deloitte — Cloud Cost Management Benchmark 2025 — Source for FinOps tooling cost range of 3–5% of cloud bill at the high end (2025)
- Forrester — Public Cloud Market Outlook 2026 — Source for $1.03 trillion projected global public cloud spend (2026)
- CloudZero — State of Cloud Cost Intelligence 2024 — Source for 30% of organisations accurately tracking cross-cloud spend (corollary: 70% cannot) (2024)
- Network World — FinOps Foundation Sharpens FOCUS to Reduce Cloud Cost Chaos — Source for FinOps Foundation community reaching 100,000 practitioners; 96 of Fortune 100 in Foundation programmes; FOCUS 1.3 Kubernetes shared cost allocation detail (December 2025)
The cloud billing schema problem is not a discipline failure. It is an architectural one. Organisations cannot optimise what they cannot measure, and they cannot measure accurately when every provider in their estate speaks a different billing language. FOCUS does not improve the normalisation workflow — it eliminates the need for one.
See DigiUsher’s FOCUS-native architecture in a 30-minute working session
DigiUsher is the FinOps Operating System built on FOCUS 1.x natively — not as a compatibility layer, but as the platform’s foundational data model. In 30 minutes, we will show you a single query surface across your full technology estate: multi-cloud infrastructure, Kubernetes, AI workloads, and SaaS — governed from one schema, one allocation model, and one source of truth.
Available on AWS Marketplace (AWS ISV Accelerate Partner), Azure Marketplace (Azure ISV Co-Sell Ready, MACC-eligible), and GCP Marketplace. SOC 2 Type II certified. GDPR compliant. BYOC deployment available for regulated industries.
Request a 30-minute session → digiusher.com/request-a-demo
Related Posts
FOCUS 1.3 Decoded: What Changed, What It Governs, and What It Means for Your FinOps Stack · 19 May 2026 The technical companion to this post — a complete anatomy of FOCUS versions 1.0 through 1.3, covering every major capability added and every enterprise use case each release unlocks.
Why DigiUsher Rebuilt Its Cost Engine on FOCUS — and Why That Decision Is Now an Enterprise Advantage · 26 May 2026 The architectural pivot story — how DigiUsher made the decision to build FOCUS-native from the ground up, and what that commitment delivers to enterprise customers in 2026.
FOCUS in Production: How DigiUsher’s FOCUS-Native Engine Delivers Real-Time Allocation, AI Token Governance, and €1M in 45 Days · 2 June 2026 The outcomes proof — what FOCUS-native architecture delivers in production, including the European energy utility’s €1M saving in 45 days and AI token attribution at regulated enterprise scale.
FOCUS Is the New Procurement Standard: How the FinOps Industry’s Billing Specification Became a Vendor Evaluation Weapon · 9 June 2026 The strategic conclusion to this series — how FOCUS conformance has become a board-level procurement criterion, and the seven evaluation questions every enterprise should put to their FinOps vendor.
Cloud Cost Optimisation Is Dead: Why FinOps Must Now Govern the Full Technology Estate · 14 April 2026 The strategic context for why billing data normalisation matters beyond cloud — as FinOps scope expands to AI, SaaS, and data platforms, a unified cost schema becomes the foundational requirement for the entire practice.
DigiUsher in 30 min
See which team owns every dollar — in real time.
DigiUsher turns raw billing data into allocation finance trusts — chargeback, showback, and guardrails included.
Book a 30-min walkthroughNo hard pitch · tailored to your stack
Continue Reading
More from the DigiUsher editorial team.
Seven Signals from the State of FinOps 2026: Why Technology Value Management Is Now a Board-Level Mandate
8% of FinOps teams now govern AI spend. Gartner forecasts $2.52T in global AI investment. The State of FinOps 2026 rewrites the rules for every CTO, CFO, and Head of FinOps.

Why DigiUsher Rebuilt Its Cost Engine on FOCUS — and Why That Decision Is Now an Enterprise Advantage (Blog 3/5 Series)
In 2023, DigiUsher bet its platform architecture on FOCUS before hyperscalers committed to it. Here is why that decision was made, what it cost, and what it delivers.
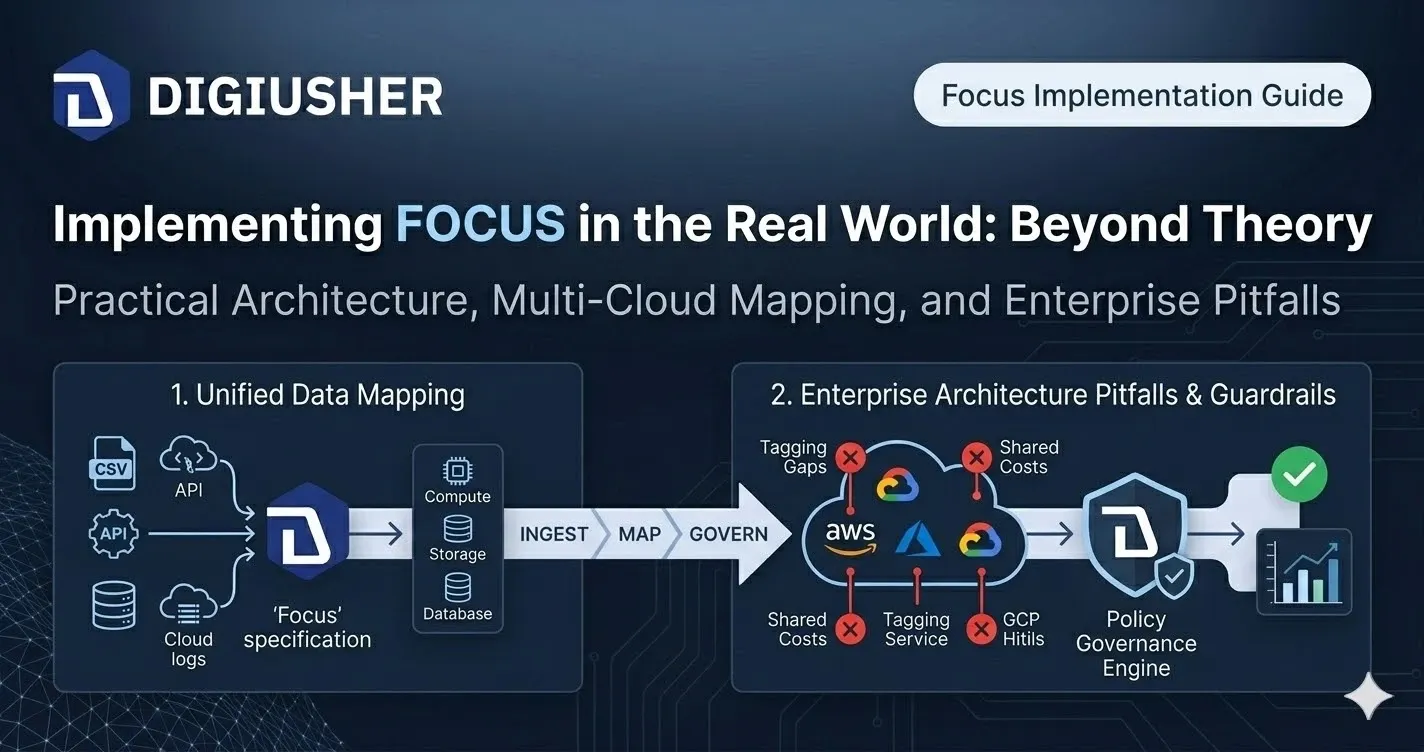
FOCUS 1.3 Decoded: What Changed, What It Governs, and What It Means for Your FinOps Stack (Blog 2/5 Series)
FOCUS 1.3 solved three problems that have defeated enterprise FinOps teams for years: shared cost allocation, contract commitment tracking, and data freshness. Here is the complete technical guide.